
Hello everyone, in this section, if you are a gopher, I believe you have already heard about Golang's ability on concurrency. But there is something different in Golang, which is you can abuse its concurrency with some style. Now, have you interested to know better about the Golang concurrency pattern? In this chapter, I will explain how we make a pipeline pattern which was the most commonly used and very simple.
First of all, we know that goroutines are cheap; they only consume 2kB each at the minimum; after knowing this, I hope you start to abuse it well. But remember, high power means we do need a big responsibility for using it. You can make whatever model you want on doing the concurrency, but the pattern comes to maximize and make it clean to be read and re-apply. I presume you already understand how to use goroutines and channels because it is the basic tool.
For the pipeline pattern, like the name itself, the easiest way to understand it is that we are making a basically sequential step of the process, and we do it concurrently. For instance, commonly, within your use cases, there are a lot of things that happen within a single flow. This concept gets along very well with one of the SOLID principles, which is Single Responsibility. Imagine that single flow, then you split it into multiple functions that do only one thing at one time and, in the end, utilized it to work concurrently with goroutines.
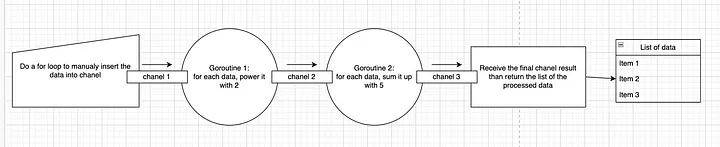
Here is a simple diagram of how the pipeline pattern works. From the image above, we want to modify a list of numbers with a few steps. First, we power it with two and then sum it with 5. For each process, summon goroutines, and each of them will communicate using channels. Each goroutine has its own purpose and job. First, the goroutine is going to produce the data into channels, then goroutine one will power up each data with 2, and next goroutine two will sum each data with 5. In the end, we collect each data from channels and return it. This is all done concurrently without waiting for each data to be processed completely in one step before going to the next step. This is the power of pipelines goroutines with channels where we can concurrently process each data without needing to wait for the other to be done.
The easiest way to understand it is by looking at the code. Here is an example of the diagram above.
package pipeline
import (
"math"
"sync"
)
type IntegerReducerParam struct {
Amount int
Power int
}
func LaunchIntegerReducer(in *IntegerReducerParam) int {
out := generator(in.Amount)
// distribute the job into 2 workers
o1 := power(out, in.Power)
o2 := power(out, in.Power)
out = merge(o1, o2)
out = sum(out)
return <-out
}
func generator(in int) <-chan int {
ret := make(chan int, in)
go func() {
for i := 0; i < in; i++ {
ret <- i
}
close(ret)
}()
return ret
}
func power(in <-chan int, pow int) <-chan int {
ret := make(chan int)
go func() {
for i := range in {
ret <- int(math.Pow(float64(i), float64(pow)))
}
close(ret)
}()
return ret
}
func sum(in <-chan int) <-chan int {
ret := make(chan int, 1)
go func() {
var sum int
for v := range in {
sum += v
}
ret <- sum
close(ret)
}()
return ret
}
func merge(ii ...<-chan int) <-chan int {
out := make(chan int)
var wg sync.WaitGroup
output := func(c <-chan int) {
defer wg.Done()
for n := range c {
out <- n
}
}
wg.Add(len(ii))
for _, i := range ii {
go output(i)
}
go func() {
wg.Wait()
close(out)
}()
return out
}so here is the thing we noted here, there are methods named fan-in and fan-out . These methods will be useful if you are going to make more than one goroutine to do a step within a flow. for example the example above, the fan-out process happened in power() function in which we are distributing the job into two goroutines. This action resulting a branching in the channels. We can either do the fan-in process that has been done by merge() function or continue to execute the pipeline by calling the next step function twice. This is because the result can go either on channels o1 or o2 .
Last but not least, don’t forget to put an context.Context in your function parameter. This is useful for stopping the goroutines from processing your data whenever an error occurs within your pipeline process. Another way is that you can be passed a channel as a flag if the process must stop because of some errors. Remember, don’t let the goroutines run all the time; they must know when to stop. From the example above, we are creating a dominos flag; when the initial channels are closed, the for loop within the goroutines will close, and we already set to close the channels after the loop. It will happen to each of the goroutines within the pipelines until all the goroutines stopped.
Conclusion
Golang has powerful support for concurrency, with its lightweight thread (even though is not). The pipeline pattern was the most commonly used. It is quite easy to use and can be implemented easily, yet it’s still readable. If you want to learn the pipeline pattern comprehensive mode, you can go here. One last piece of advice is don’t overuse it; the silver bullets don’t mean for every enemy you met.

